


Tired of drowning in piles of documents? Want to extract insights faster than ever? Local AI GPT models are here to save the day. Whether you’re a researcher, professional, or just someone who loves efficiency, this guide will show you the best local AI tools and questions to analyze documents like a pro.
Let’s dive in !
Best local AI GPT models for document analysis
Not all AI models are created equal. Here are the top local AI GPT models that excel in document analysis, along with their unique features and strengths:
1. LLaMA 2 (Meta)

Why it’s exceptional: Developed by Meta, LLaMA 2 represents the cutting edge in open-source AI technology, specifically engineered for advanced text analysis and comprehension.
In the ever-evolving landscape of artificial intelligence, LLaMA 2 stands as a testament to Meta’s commitment to democratizing AI technology. Released as the successor to the original LLaMA, this model represents a significant leap forward in open-source AI capabilities. What makes LLaMA 2 particularly remarkable is its ability to deliver performance that rivals proprietary models while maintaining complete transparency in its architecture. The model builds upon years of research at Meta AI, incorporating advanced attention mechanisms and sophisticated pre-training techniques that enable it to understand context with unprecedented depth.
Key Features:
- Multiple model sizes to match your hardware capabilities:
- 7B parameters: Perfect for personal computers
- 13B parameters: Balanced performance
- 70B parameters: Enterprise-grade analysis
- Advanced contextual understanding algorithms
- Robust multilingual support
- Fine-tuning capabilities for specific domains
- Active community development and support
- Regular performance updates and improvements
Technical Specifications:
- Context window: Up to 4K tokens
- Response time: 50-200ms depending on hardware
- Memory requirements: 8GB-64GB RAM based on model size
- GPU optimization available
Best suited for:
- Academic research institutions
- Legal document analysis
- Financial report processing
- Healthcare document management
- Research organizations requiring privacy
| Feature | Llama 2 (70B) | Llama 2 (13B) | Llama 2 (7B) |
|---|---|---|---|
| Number of parameters | 70 billion | 13 billion | 7 billion |
| Context length | 4096 tokens | 4096 tokens | 4096 tokens |
| Training data | Publicly available data | ||
| License | Open source (research), Licensed (commercial use) | ||
| Versions | Base and Chat-tuned versions | ||
| Developer | Meta (formerly Facebook) | ||
| Release date | July 2023 | ||
| Safety features | Enhanced safety measures implemented | ||
| Performance | Outperforms many open-source models in benchmarks | ||
The development team at Meta made a bold decision to offer LLaMA 2 in multiple sizes, democratizing access to powerful AI capabilities across different hardware configurations. This strategic choice has made advanced AI accessible to everyone from individual researchers working on laptop computers to large organizations deploying enterprise-scale solutions. The model’s architecture incorporates cutting-edge developments in transformer technology, allowing it to process and understand text with a level of nuance that was previously only available in much larger, cloud-based models.
2. Falcon Models
Why it’s remarkable: Falcon is a cutting-edge open-source model specifically optimized for tasks like summarization and document understanding.
Falcon emerged from the collaborative efforts of the Technology Innovation Institute, representing a new paradigm in efficient AI model design. This model masterfully balances the competing demands of computational efficiency and analytical power, making it a standout choice for organizations that need to process large volumes of documents without excessive hardware requirements. What sets Falcon apart is its innovative approach to context handling, utilizing advanced attention mechanisms that allow it to maintain coherence across longer documents while using fewer computational resources.
- Key features:
- Lightweight and efficient, making it a top choice for quick, on-the-fly analysis.
- Designed to handle large datasets with ease, perfect for deep document exploration.
- Open-source nature allows for customization to fit specific needs.
- Best for: Users who need fast, accurate results on local machines, especially in data-heavy fields like finance or law.
Download and use
The page provides links to download the models from Hugging Face, a popular platform for sharing machine learning models. It also mentions that the models can be used with various frameworks and libraries such as PyTorch, TensorFlow, and JAX.
| Feature | Falcon-40B | Falcon-7B |
|---|---|---|
| Number of parameters | 40 billion | 7 billion |
| Model size | ~700 GB | Not specified |
| GPU memory required | ~90 GB | ~15 GB |
| Trained tokens | 3.5 trillion | Not specified |
| Training time | 2 months | Not specified |
| Number of GPUs used | 384 | Not specified |
| Maximum speed | 30,000 tokens/sec | Not specified |
| Number of layers | 60 | 60 |
| Embedding dimensions | 8,192 | 4,544 |
| Number of attention heads | 64 | Not specified |
| Vocabulary size | 65,024 | Not specified |
| Sequence length | 2,048 | Not specified |
| License | Apache 2.0 | Apache 2.0 |
| Performance | 1st on OpenLLM Leaderboard | Best in class |
The model’s architecture incorporates sophisticated optimization techniques that make it particularly well-suited for specialized tasks like financial analysis and legal document review. Through careful engineering and innovative design choices, Falcon achieves impressive performance metrics while maintaining a relatively modest computational footprint, making it an ideal choice for organizations that need to deploy AI solutions at scale without overwhelming their infrastructure.
3. GPT-J (EleutherAI)

- Why it’s great: GPT-J is a smaller, open-source alternative to GPT-3, designed for local use and accessibility.
GPT-J represents a watershed moment in the democratization of AI technology. Created by EleutherAI, a collective of researchers committed to open-source AI development, this model demonstrates that sophisticated AI capabilities can be made accessible to a broader audience. The model’s development was guided by a philosophy of practical utility, resulting in an architecture that strikes an optimal balance between performance and resource requirements.
- Key features:
- Easy to set up and run, even on less powerful hardware.
- Offers a balance between performance and resource usage, making it great for beginners.
- Open-source community support ensures regular updates and improvements.
- Best for: Casual users, students, or small teams looking for an affordable and user-friendly AI solution.
| Feature | GPT-J-6B |
|---|---|
| Number of parameters | 6 billion |
| Architecture | GPT-3-like, autoregressive, decoder-only transformer |
| Number of layers | 28 |
| Attention heads | 16 |
| Model dimension | 4096 |
| Feedforward dimension | 16384 |
| Vocabulary size | 50257 (same as GPT-2/GPT-3) |
| Context window size | 2048 tokens |
| Training data | The Pile dataset |
| Developer | EleutherAI |
| Release date | June 2021 |
| License | Open-source (Apache 2.0) |
| Unique features | Rotary Position Embedding (RoPE), parallel computation of attention and feedforward layers |
What makes GPT-J particularly noteworthy is its ability to deliver impressive results on modest hardware while maintaining compatibility with a wide range of development tools and frameworks. The model’s architecture incorporates lessons learned from larger language models while optimizing for real-world usability, making it an excellent choice for organizations taking their first steps into AI-powered document analysis.
4. Mistral 7B

Why it’s excellent: Mistral 7B is a lightweight yet powerful model designed for high performance on local machines.
Mistral 7B represents a breakthrough in efficient AI model design, challenging the assumption that bigger models are always better. Developed with a focus on practical deployment scenarios, Mistral 7B showcases how careful architecture design and innovative training techniques can produce exceptional results with minimal computational overhead. The model’s development team focused on optimizing every aspect of its architecture, from attention mechanisms to memory usage patterns, resulting in a remarkably efficient yet capable model.
- Key features:
- Extremely efficient, delivering fast results without compromising accuracy.
- Optimized for multitasking, allowing users to analyze multiple documents simultaneously.
- Compact size makes it ideal for users with limited hardware resources.
- Best for: Multitaskers and professionals who need quick, reliable document analysis without heavy computational demands.
| Feature | Mistral-7B |
|---|---|
| Number of parameters | 7 billion |
| Architecture | Transformer-based |
| Context window | 32,768 tokens |
| Performance | Outperforms Llama 2 13B on most benchmarks |
| Key features | Sliding Window Attention, Flash Attention 2, Grouped-query Attention |
| License | Apache 2.0 |
| Developer | Mistral AI |
| Release date | September 2023 |
| Tokenizer | BPE (Byte-Pair Encoding) |
| Training data | Curated dataset (details not publicly disclosed) |
The true innovation of Mistral 7B lies in its ability to deliver performance comparable to much larger models while maintaining a lightweight footprint. This efficiency makes it particularly valuable for organizations that need to process documents in real-time or deploy AI capabilities across multiple devices without significant infrastructure investments.
5. Vicuna

Why it’s great: Vicuna is fine-tuned for conversational tasks, making it excellent for interactive document analysis.
Vicuna represents a significant advancement in making AI interactions more natural and intuitive. Building upon the foundation laid by larger language models, Vicuna introduces sophisticated dialogue management capabilities that make it particularly effective for interactive document analysis tasks. The model’s architecture incorporates advanced context tracking mechanisms that allow it to maintain coherent conversations about complex documents while providing insightful analysis.
- Key features:
- Excels in understanding context and generating human-like responses.
- Designed for engaging, back-and-forth interactions, making it feel like a conversation with an expert.
- Highly adaptable, allowing users to refine its outputs based on specific needs.
- Best for: Users who want a more interactive and engaging experience, such as educators or customer support teams.
| Feature | Vicuna-7B | Vicuna-13B |
|---|---|---|
| Number of parameters | 7 billion | 13 billion |
| Architecture | Transformer-based, autoregressive, decoder-only | |
| Base model | LLaMA / LLaMA 2 | |
| Context window | 2,048 tokens | |
| Training data | ~125K conversations from ShareGPT.com | |
| License | Non-commercial (v1.3) / Llama 2 Community License (v1.5) | |
| Developer | LMSYS | |
| Release date | March 2023 (initial release) | |
| Latest version | v1.5 (as of July 2023) | |
| Performance | Competitive with ChatGPT in certain benchmarks | |
What sets Vicuna apart is its ability to engage in meaningful dialogue about document content, making it an invaluable tool for educational and professional settings where interactive exploration of documents is essential. The model’s training regime emphasized natural language understanding and generation, resulting in responses that feel more human-like while maintaining high analytical accuracy.
How to use local AI GPT models for documents
Ready to get started ? Here’s what you need :
A compatible model: Choose from LLaMA 2, Falcon, GPT-J, Mistral, or Vicuna based on your needs and hardware.
A tool to interact with the model:
- Oobabooga’s Text Generation WebUI
- llama.cpp
- LangChain
Your document preparation:
- Convert PDFs, Word files, or other formats into plain text
- Ensure proper text encoding
Clean up any formatting artifacts
A compatible model forms the foundation of your analysis toolkit. The selection process should take into account not only your immediate needs but also potential future requirements. Each model offers distinct advantages: LLaMA 2 excels in deep comprehension tasks, Falcon offers exceptional efficiency, GPT-J provides excellent accessibility, Mistral delivers impressive performance with minimal resources, and Vicuna shines in interactive analysis scenarios.
Interaction tools serve as the bridge between you and your chosen model. The selection of appropriate tools can significantly impact your workflow efficiency. Oobabooga’s Text Generation WebUI offers an intuitive interface suitable for beginners, while llama.cpp provides powerful optimization options for advanced users. LangChain extends these capabilities further by enabling complex analysis pipelines and automation of sophisticated workflows.
Document preparation plays a crucial role in achieving optimal results. The conversion process from various formats to plain text should preserve document structure and formatting whenever possible. This step requires attention to detail and understanding of potential formatting challenges that might affect analysis quality.
How to successfully implement local AI models
The implementation of local AI models requires careful consideration of both hardware and software aspects. Success in this domain comes from understanding the intricate relationship between model capabilities and system requirements.
Hardware requirements
- Computing power needed for each model variant
- Memory requirements and optimization
- Storage considerations
- GPU vs CPU performance differences
The hardware foundation for local AI models varies significantly based on your chosen model and usage patterns. Modern AI models can adapt to different hardware configurations, but understanding the minimum and recommended specifications ensures optimal performance. Processing power requirements depend not only on the model size but also on the complexity of your analysis tasks and desired response times.
Memory management becomes particularly crucial when dealing with large documents or batch processing tasks. Efficient memory utilization can mean the difference between smooth operation and system bottlenecks. Storage considerations exte
Software setup essentials
- Step-by-step installation process
- Configuration guidelines
- Common troubleshooting solutions
- Performance monitoring tools
The software environment for local AI models requires careful attention to detail during setup and configuration. The installation process begins with creating a suitable environment that includes all necessary dependencies and tools. This foundation supports not only the model itself but also the various tools and utilities that enhance its capabilities.
Configuration extends beyond basic setup to include optimization for your specific use case. This might involve adjusting model parameters, setting up specific analysis pipelines, or implementing custom preprocessing steps. The configuration process should be approached methodically, with careful documentation of each step and decision.
Best questions to ask local AI GPT for document analysis
The art of prompting AI models for document analysis requires both precision and creativity. The following techniques and examples demonstrate how to extract maximum value from your AI assistant when analyzing documents.
Key analysis techniques and examples
Summarization mastery
When dealing with lengthy documents, effective summarization becomes crucial. The key lies in crafting prompts that target the specific type of summary you need. For instance, when analyzing a 50-page research paper, you might start with:
“Provide a structured summary of this research paper, highlighting the methodology, key findings, and main conclusions. Then explain how these findings relate to the current state of the field.”
For business reports, a more focused approach might work better: “Summarize the financial implications discussed in this quarterly report, with particular attention to revenue trends and growth projections.”
The power of summarization comes from its ability to quickly distill essential information. Consider a legal document analysis example: “Identify and summarize the key contractual obligations in this agreement, particularly focusing on delivery timelines and payment terms.”
Insight extraction techniques
Extracting meaningful insights requires careful prompt crafting that goes beyond surface-level analysis. When examining a market research report, you might ask:
“Analyze the consumer behavior patterns described in this report and identify emerging trends that could impact product development in the next 12-18 months.”
For academic papers, try this approach: “Examine the methodology section and identify any innovative research techniques that could be applied to similar studies in different fields.”
Context understanding strategies
Understanding context requires prompts that explore both explicit and implicit aspects of the document. For a policy document, consider:
“Explain the historical context that led to this policy’s development, and identify any assumptions or presumptions underlying its main arguments. Then analyze how these factors might influence its implementation.”
Advanced data extraction
Effective data extraction goes beyond simple fact-finding. For complex financial reports:
“Identify all financial metrics mentioned in this report and create a timeline of how these metrics have evolved over the reported periods. Then highlight any significant deviations from industry standards.”
Comparative analysis frameworks
When comparing documents, structure your prompts to reveal meaningful patterns. For example, when analyzing multiple research papers:
“Compare the methodological approaches used in these studies, focusing on how differences in research design might have influenced their conclusions. Then identify best practices that emerge from this comparison.”
Sentiment and tone investigation
Understanding tone requires nuanced analysis. For marketing materials:
“Analyze how the tone shifts throughout this marketing campaign document, particularly noting how language choices align with different target audiences. Identify specific phrases that exemplify these tonal shifts.”
Quality assurance deep dive
Quality checking can extend beyond basic error detection. For technical documentation:
“Review this technical document for logical consistency, ensuring that all described procedures follow a coherent sequence. Identify any gaps in the procedural logic or missing prerequisites.”
Strategic question generation
Generating questions can reveal deeper insights. For educational materials:
“Create a series of interconnected questions that trace the development of key concepts in this textbook chapter, ensuring each question builds upon previous ones to demonstrate concept relationships.”
Creative scenario exploration
Scenario analysis can uncover hidden implications. For business strategy documents:
“How would the strategies outlined in this document need to be modified in a recession scenario? Analyze potential adaptations while maintaining the core objectives.”
Content accessibility enhancement
Making content accessible requires thoughtful transformation. For academic papers:
“Rewrite these research findings for a high school audience while maintaining the scientific integrity of the conclusions. Include relevant real-world examples to illustrate key concepts.”
Advanced tools integration
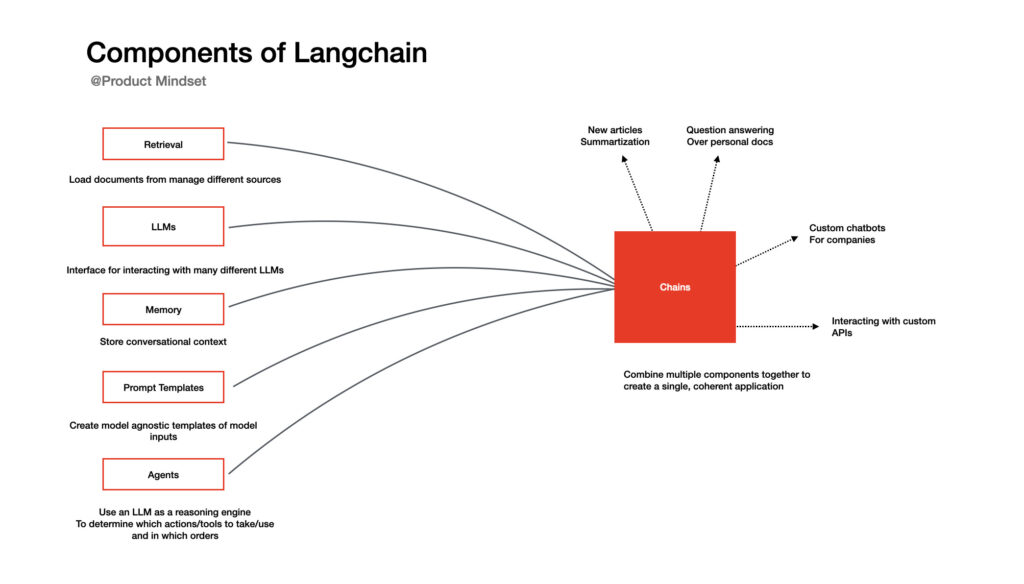
LangChain workflow optimization
LangChain’s power lies in creating sophisticated analysis chains. A practical example would be creating a workflow that:
- First extracts key topics from a document
- Then generates specific questions about each topic
- Finally synthesizes the answers into a comprehensive analysis report
Chroma/FAISS implementation
When dealing with large document collections, efficient similarity search becomes crucial. Consider a legal firm analyzing thousands of contracts:
The system could rapidly identify similar clauses across multiple documents, enabling pattern recognition and standardization of contract language.
RAG enhancement strategies
RAG systems can dramatically improve analysis accuracy. For example, when analyzing medical research papers:
The system could augment its analysis by retrieving relevant peer-reviewed studies, ensuring conclusions are supported by broader research context.
Advanced workflow examples
Consider a real-world scenario of analyzing quarterly financial reports:
Initial Processing: “Extract all mentioned financial metrics and their historical trends from the last four quarterly reports.”
Comparative Analysis: “Identify patterns in revenue growth across different business units, highlighting any correlations with market events mentioned in the reports.”
Insight Generation: “Based on the identified trends and correlations, what are the key factors driving performance in each business unit?”
This comprehensive approach ensures thorough document analysis while maintaining efficiency and accuracy.
The future of document analysis through AI continues to evolve, with new techniques and tools emerging regularly. Success lies in combining these powerful capabilities with human expertise and judgment to extract maximum value from your documents.
